Why ChatGPT Isn’t Citing Your Website
Your website doesn’t appear in ChatGPT answers for one of eight reasons: OpenAI’s crawler is blocked in your robots.txt, your content is missing from Bing’s index (which powers ChatGPT’s browsing), your pages lack direct answers in the right structural positions, or your domain authority is too low for ChatGPT to treat you as a citable source. The fix for each is different and some take minutes, while others take months.
This post breaks down every reason with specific evidence and tells you what to prioritise first.
How ChatGPT actually finds and cites content
Before diagnosing the problem, you need to understand the two distinct ways ChatGPT sources information because most guides conflate them.
Training data – The base model is trained on a large corpus of text crawled from the web. GPT-3’s training data was over 80% derived from Common Crawl, a nonprofit that has been archiving the public web since 2008. This data has a cutoff the model doesn’t know about content published after training ended. Your site may simply have never been included.
Browsing mode – When ChatGPT has web browsing enabled, it uses Microsoft Bing’s search index to retrieve live pages. It doesn’t crawl independently in real time, it queries Bing and reads the results. This means if your page doesn’t rank in Bing, a browsing-enabled ChatGPT can’t find it either.
Understanding this split matters because the fixes are completely different. A robots.txt problem affects the crawler; a Bing indexing problem affects browsing. Most websites have both.
Reason 1 – GPTBot is blocked in your robots.txt
OpenAI launched GPTBot, its official web crawler, in August 2023. Its job is to crawl publicly accessible web pages so the content can be used to train and improve future models.
The problem: a surprisingly large number of websites block it. Research from Originality.ai found that 26% of the top 1,000 websites had blocked GPTBot. Among news publishers, BuzzStream found that 62% of top news sites block GPTBot entirely. Many of these blocks weren’t intentional they came from blanket “block all crawlers” rules or outdated configurations from before GPTBot existed.
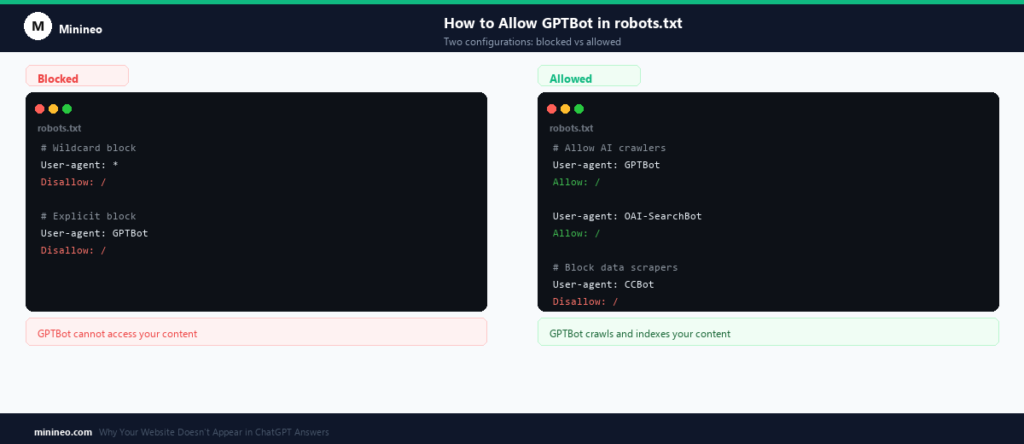
How to check: Open your robots.txt file at yourdomain.com/robots.txt. Look for any of these:
User-agent: GPTBotDisallow: /User-agent: *Disallow: /The second entry blocks everything, including GPTBot, even if it doesn’t name it.
How to fix it: Either remove the block or explicitly allow GPTBot while keeping other restrictions in place:
User-agent: GPTBotAllow: /OpenAI’s official GPTBot documentation explains exactly how to configure this. You’ll also want to check for OAI-SearchBot, which is OpenAI’s crawler for SearchGPT and ChatGPT’s real-time search feature.
Reason 2 – Your site isn’t in Bing’s index
This is the most overlooked problem. SEOs spend years optimising for Google and almost no time thinking about Bing. But ChatGPT’s browsing feature uses Bing’s search index, not Google’s. A page that ranks on Google page 1 but doesn’t exist in Bing is invisible to a browsing-enabled ChatGPT.
Bing’s index is smaller and crawls less aggressively than Google’s. New pages, low-authority domains, and sites with poor internal linking often go weeks or months without Bing discovering them.
How to fix it: Submit your sitemap directly to Bing Webmaster Tools. It’s free, takes 10 minutes, and you can submit individual URLs for immediate indexing. Once you’re set up, Bing’s IndexNow protocol lets you push new URLs the moment they’re published which also syndicates to other IndexNow participants automatically.
Reason 3 – Your content doesn’t open with a direct answer
AI engines parse pages the same way a researcher skimming a document does they look at the first sentence of each section to decide if it answers the query. If your first paragraph is a preamble (“In this post, we’ll be exploring…”), a vague context-setter, or a description of what the article covers, the AI has nothing to extract.
The fix is structural, not a rewrite. Every page on your site should open with a direct, definitional sentence that answers the main topic immediately. For a page about keyword density, the first sentence should define what keyword density is and give the key number. For a guide about schema markup, the first sentence should say what schema markup is. Not “Schema markup is an interesting topic that many SEOs overlook” that’s worthless to an AI.

Specifically: the first 150 words carry disproportionate weight. This is the section AI engines prioritise when deciding whether a page answers a query well enough to cite.
What good looks like:
Schema markup is structured data added to a web page written in JSON-LD format that tells search engines and AI engines exactly what the content is about. It uses vocabulary from Schema.org and is placed in a
<script>tag in the page’s<head>section.
What doesn’t work:
If you’ve been struggling to get your website noticed by search engines and AI tools, schema markup might be the missing piece of your strategy.
The second version is read and discarded. The first version gets cited.
Reason 4 – Low domain authority
ChatGPT disproportionately cites sources with established authority. SE Ranking’s analysis of over 129,000 domains found a strong correlation between referring domain count and citation frequency: sites with 350,000+ referring domains averaged 8.4 ChatGPT citations per query, while sites with under 2,500 referring domains averaged 1.6 to 1.8.
This isn’t unfixable but it’s not a quick fix either. Domain authority is built through consistent publication of cited content, earning backlinks from authoritative sources, and establishing topical depth across a subject area.
The practical implication: if your domain is relatively new or has a thin backlink profile, ChatGPT will cite your content less even if it’s well-structured. The structural improvements in this post still matter, but they work faster once you have a foundation of authority.
What you can do now: Focus on earning links from industry publications, directories, and relevant blogs. Write content that references verifiable data pages with specific stats earn more backlinks than opinion pieces.
Reason 5 – Pages are too short or too vague
The same SE Ranking study found that content depth correlates with citation frequency. Pages over 2,900 words averaged 5.1 citations; pages under 800 words averaged 3.2. That’s not a coincidence longer pages cover more sub-topics, answer more related questions, and include more specific language that AI engines can extract.
Vague language is equally damaging. Sentences like “keyword density should be appropriate for your content” give AI engines nothing to quote. Sentences like “keyword density above 3.5% risks triggering Google’s spam detection algorithms” are specific, attributable, and citable.
Go through your existing pages and look for:
- Paragraphs with no specific numbers, named tools, or named methodologies
- Sections that describe what to do without explaining how
- Any page under 600 words covering a topic that has real search demand
These are your lowest-hanging fruit for GEO improvements.
Reason 6 – Headings don’t match how AI parses structure
AI engines use heading tags to map page structure. An H2 heading tells the AI “this section answers a sub-question about the main topic.” If your H2s are descriptive statements (“Benefits of Schema Markup”) rather than questions (“Does schema markup help SEO?”), the AI has a harder time matching your section to a user query.
The fix is straightforward: rewrite your H2 headings as questions where it makes sense. Not every heading needs to be a question but pillar content, FAQs, and guide-style posts should have at least 3 to 4 question-format headings.
Also check whether your pages include:
- A “What is [topic]?” section with a clean definition
- An FAQ section at the bottom with 4 to 6 questions
- A clear H1 that matches the page’s primary keyword
Use the free H1 Tag Checker to audit any page’s heading structure quickly.
Reason 7 – No schema markup
Structured data doesn’t guarantee AI citations, but the evidence suggests it helps. A controlled experiment published by Search Engine Land tested pages with well-implemented schema, poor schema, and no schema. The well-structured schema page appeared in Google’s AI Overview; the no-schema page was never indexed.
The most impactful schema types for AI visibility:
- FAQPage – marks up your Q&A sections so AI engines can extract individual questions and answers as discrete units
- Article – signals publication date, author, and content type
- HowTo – structures step-by-step content in a format AI engines can parse directly
Adding these doesn’t require a developer. Use the free Schema Markup Generator to generate valid JSON-LD for any of these types, then paste the output into your page’s <head>.
Reason 8 – No llms.txt file
llms.txt is a plain-text file placed at the root of your domain (e.g. yourdomain.com/llms.txt) that tells AI crawlers which pages on your site are most important, what your site is about, and how to navigate your content. It’s similar to robots.txt, but designed specifically for large language models rather than traditional search crawlers.
It was proposed by Jeremy Howard of fast.ai in September 2024, and adoption is growing quickly as AI companies look for structured ways to understand the sites they crawl. It won’t immediately fix your ChatGPT visibility it’s one signal among many but it’s a 10-minute implementation that no-cost alternative exists for.
Use the free LLM.txt Generator to build a properly formatted file and validate an existing one.
What to fix first – a priority order
Not all of these carry equal weight, and some take far longer than others. Here’s a realistic sequence:
This week (30 minutes or less):
- Check and fix your robots.txt remove any GPTBot blocks
- Submit your sitemap to Bing Webmaster Tools
- Add FAQPage schema to your three most important pages
This month:
4. Rewrite opening paragraphs on key pages to lead with a direct definition or answer
5. Convert H2 headings to question format on pillar content
6. Add llms.txt to your domain root
7. Audit and expand any pages under 800 words that cover high-value topics
Ongoing:
8. Build topical authority through consistent publication and link acquisition
ChatGPT had over 900 million weekly active users as of February 2026, and AI-driven referral traffic grew 357% in a single year. The sites doing this work now will have a 12 to 18 month compounding advantage over those who start later.
Frequently Asked Questions
Most likely because they have higher domain authority (more referring domains), longer and more structured content, or GPTBot access that your site doesn’t have. Check your robots.txt first, then compare content depth and structure on pages where they appear and you don’t.
There’s no fixed timeline. Fixes like unblocking GPTBot affect future training data crawls, which happen on a cycle tied to model updates not instantly. Browsing-mode citations can happen faster once your pages are in Bing’s index and structured correctly.
Not necessarily. Google rankings and ChatGPT citations use overlapping but different signals. Domain authority and content depth matter for both. But structural factors specific to AI (direct answer openings, question headings, schema markup) matter more for ChatGPT than for Google ranking alone.
No. ChatGPT citations are organic there is no paid placement in ChatGPT’s response sources. The only path to appearing is earning it through content quality, authority, and structure.
GPTBot is OpenAI’s official web crawler, launched in August 2023. It crawls publicly accessible web pages to gather training data for OpenAI’s language models. You can allow or block it via your robots.txt file. OpenAI’s full documentation is here.


